Статистика
Анализ данных, статистический вывод и построение предсказательных моделей
Статистика в машинном обучении
Статистика предоставляет инструменты для анализа данных, извлечения закономерностей и проверки гипотез. В машинном обучении статистические методы используются на всех этапах: от исследовательского анализа данных до оценки качества моделей и интерпретации результатов. Понимание статистики критично для правильного применения алгоритмов машинного обучения и избежания распространенных ошибок.
Почему статистика важна для AI?
Машинное обучение по сути является статистическим обучением. Мы используем статистические методы для извлечения закономерностей из данных, построения моделей и оценки их качества. Без понимания статистики легко сделать неправильные выводы из данных или построить модели, которые не обобщаются на новые данные.
Статистика помогает нам понять, насколько надежны наши выводы. Когда мы говорим, что модель имеет точность 95%, статистика позволяет оценить доверительный интервал для этой оценки и понять, насколько она может варьироваться на новых данных. Это критично для принятия обоснованных решений на основе моделей машинного обучения.
Более того, многие алгоритмы машинного обучения имеют глубокие корни в статистике. Линейная регрессия, логистическая регрессия, наивный байесовский классификатор - все это статистические методы, которые были адаптированы и расширены для задач машинного обучения. Понимание статистических основ этих методов помогает правильно их применять и интерпретировать результаты.
Основные концепции
Рассмотрим ключевые статистические концепции, необходимые для машинного обучения.
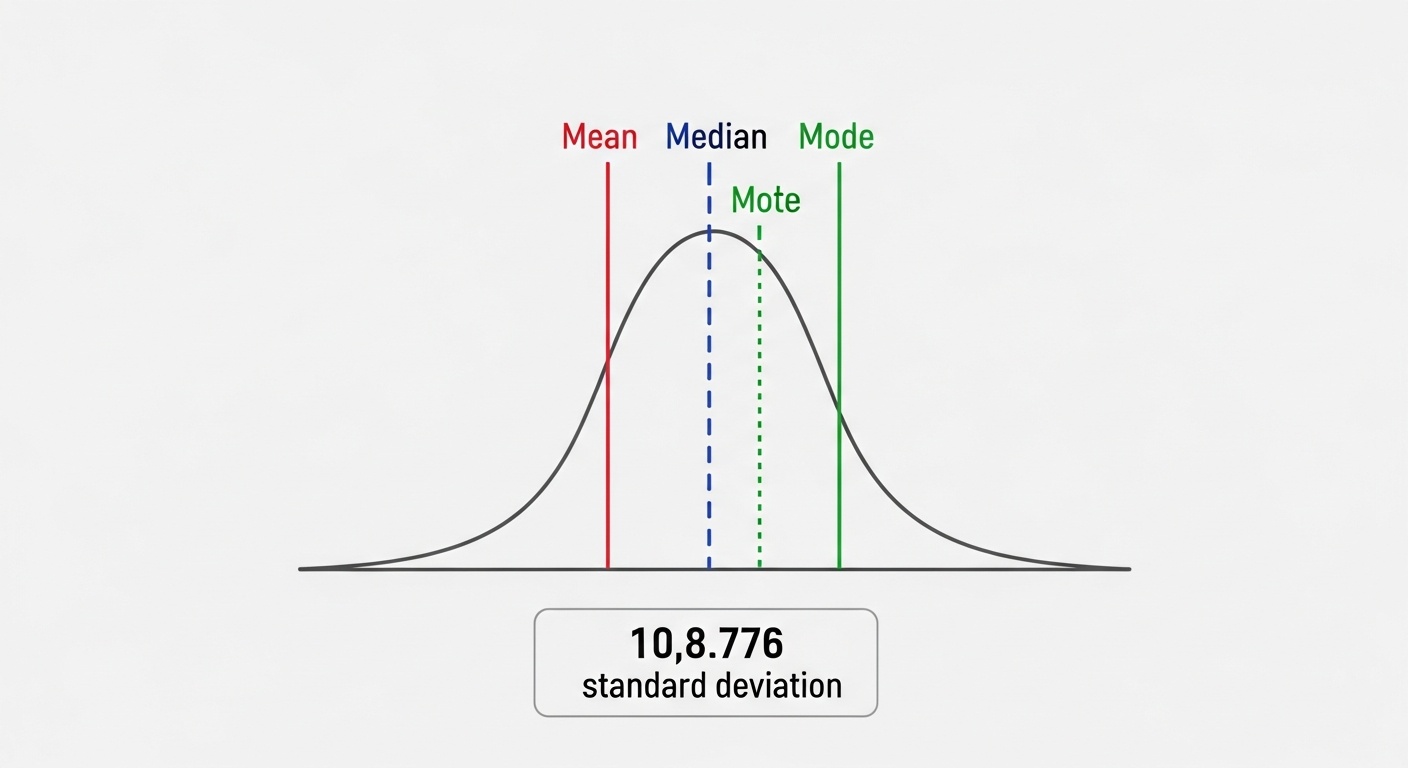
Описательная статистика
Описательная статистика суммирует и описывает основные характеристики данных. Меры центральной тенденции (среднее, медиана, мода) показывают типичное значение. Меры разброса (дисперсия, стандартное отклонение, межквартильный размах) показывают, насколько данные разбросаны.
Понимание описательной статистики критично для исследовательского анализа данных. Прежде чем строить модели, важно понять структуру данных, выявить выбросы, понять распределения признаков. Это помогает выбрать подходящие методы предобработки и моделирования.
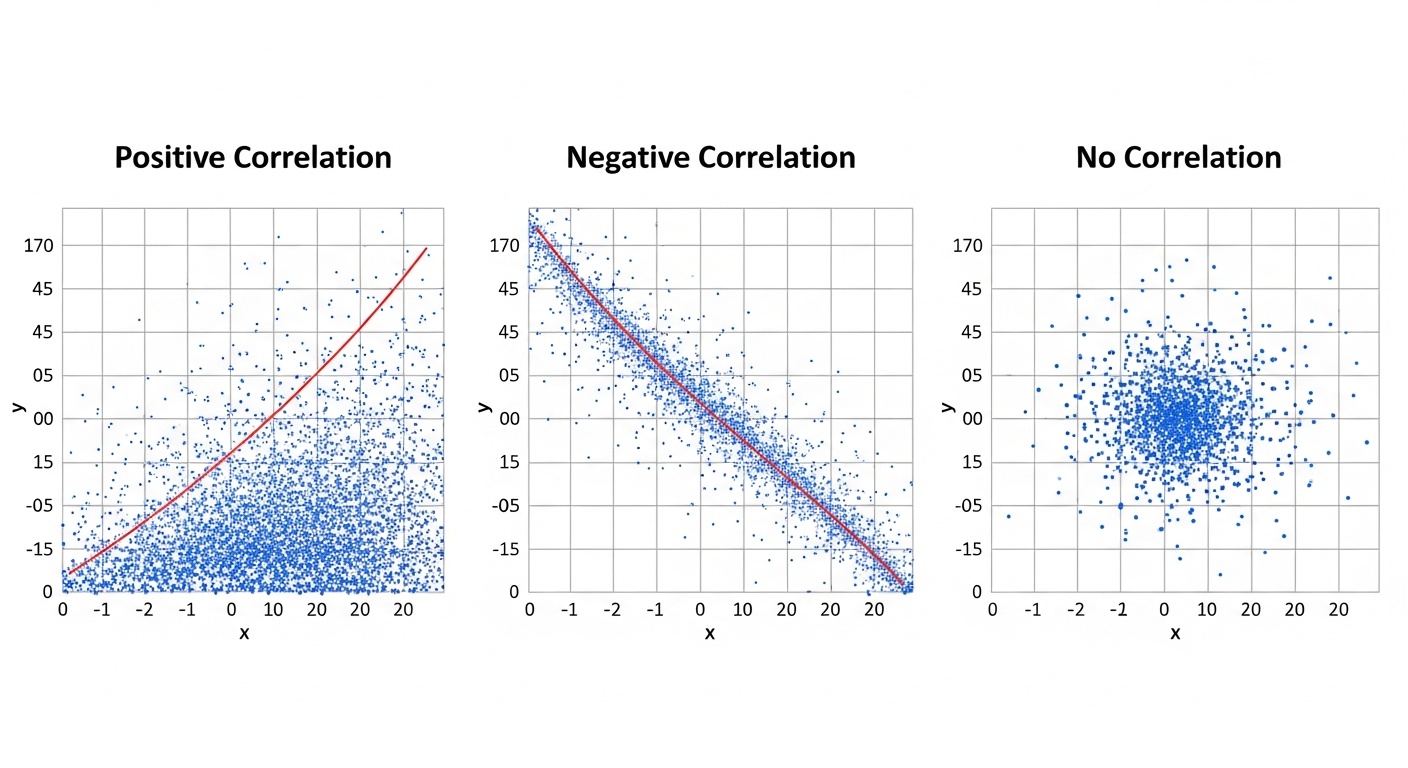
Корреляция и причинность
Корреляция измеряет линейную связь между двумя переменными. Коэффициент корреляции Пирсона варьируется от -1 (идеальная отрицательная корреляция) до +1 (идеальная положительная корреляция). Ноль означает отсутствие линейной связи.
Важно помнить: корреляция не означает причинность. Две переменные могут быть коррелированы без причинно-следственной связи. Это может быть совпадением или результатом влияния третьей переменной. Понимание этого различия критично для правильной интерпретации результатов моделей.
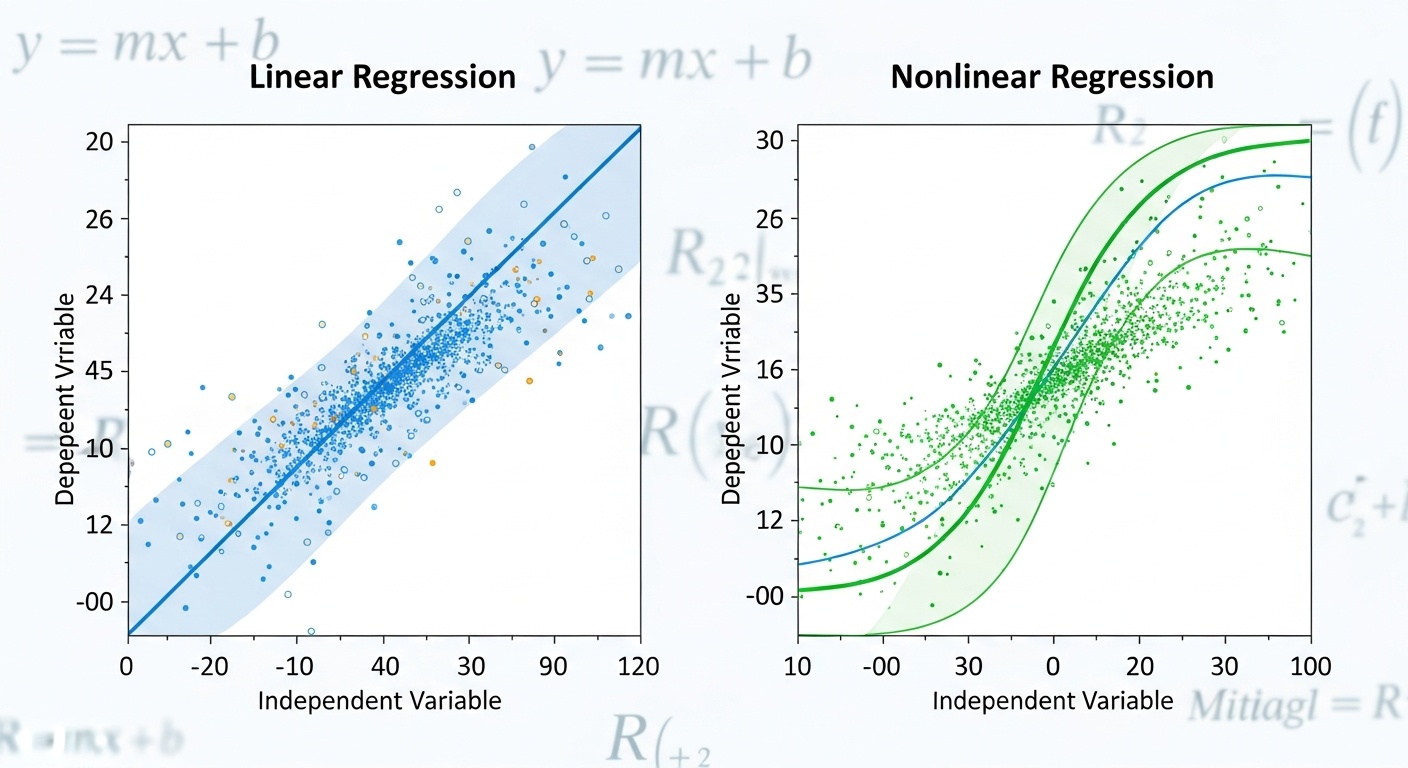
Регрессионный анализ
Регрессия моделирует зависимость между зависимой переменной и одной или несколькими независимыми переменными. Линейная регрессия предполагает линейную зависимость, но существуют и нелинейные методы регрессии.
Регрессионный анализ - один из основных методов машинного обучения. Он используется для предсказания непрерывных величин, таких как цены, температура, продажи. Понимание регрессии помогает понять многие более сложные модели, которые являются ее обобщениями.
Проверка гипотез
Статистическая проверка гипотез позволяет делать обоснованные выводы о генеральной совокупности на основе выборки. Мы формулируем нулевую гипотезу и альтернативную гипотезу, затем используем статистические тесты для принятия решения.
P-значение показывает вероятность получить наблюдаемые данные (или более экстремальные) при условии, что нулевая гипотеза верна. Малое p-значение (обычно < 0.05) дает основания отвергнуть нулевую гипотезу. Это важно для A/B тестирования и оценки статистической значимости результатов.
Применение в машинном обучении
Статистические методы широко применяются на всех этапах работы с машинным обучением.
Исследовательский анализ данных
Перед построением моделей важно понять структуру данных. Описательная статистика, визуализация распределений, анализ корреляций помогают выявить закономерности, выбросы и проблемы в данных. Это критический этап, который часто определяет успех всего проекта машинного обучения.
Гистограммы показывают распределение отдельных признаков. Диаграммы рассеяния помогают визуализировать связи между парами признаков. Ящики с усами (box plots) эффективно показывают медиану, квартили и выбросы. Корреляционные матрицы дают общую картину взаимосвязей между всеми признаками.
Оценка качества моделей
Статистика предоставляет инструменты для оценки качества моделей. Для задач регрессии используются метрики, такие как среднеквадратичная ошибка (MSE), средняя абсолютная ошибка (MAE), коэффициент детерминации (R²). Для классификации - точность, полнота, F1-мера, AUC-ROC.
Важно не только вычислить метрики, но и понять их доверительные интервалы. Кросс-валидация позволяет оценить, насколько стабильны результаты модели на разных подвыборках данных. Это помогает обнаружить переобучение и оценить способность модели к обобщению.
Выбор признаков
Статистические методы помогают выбрать наиболее информативные признаки для модели. Корреляционный анализ показывает, какие признаки сильно связаны с целевой переменной. Статистические тесты (t-тест, хи-квадрат) помогают определить, значимо ли признак связан с целью.
Удаление нерелевантных признаков может улучшить качество модели, уменьшить переобучение и ускорить обучение. Методы, такие как рекурсивное исключение признаков (RFE) или LASSO регрессия, используют статистические принципы для автоматического выбора признаков.
A/B тестирование
A/B тестирование - это статистический метод для сравнения двух версий продукта или модели. Пользователи случайным образом делятся на группы, каждая из которых видит свою версию. Затем статистические тесты используются для определения, есть ли значимая разница в метриках между группами.
Правильное проведение A/B тестов требует понимания статистики. Нужно определить размер выборки, учесть множественное тестирование, правильно интерпретировать p-значения. Ошибки в A/B тестировании могут привести к неправильным бизнес-решениям.
Важные статистические методы
Некоторые статистические методы особенно важны для машинного обучения.
T-тест
Используется для сравнения средних значений двух групп. Помогает определить, значимо ли различаются группы. Часто применяется в A/B тестировании для сравнения метрик между контрольной и экспериментальной группами.
Хи-квадрат тест
Используется для проверки независимости категориальных переменных. Помогает определить, связаны ли два категориальных признака. Применяется для выбора признаков в задачах классификации с категориальными данными.
ANOVA
Дисперсионный анализ используется для сравнения средних значений трех или более групп. Помогает определить, есть ли значимые различия между группами. Обобщение t-теста на случай множественных групп.
Доверительные интервалы
Доверительный интервал дает диапазон значений, в котором с определенной вероятностью (обычно 95%) находится истинное значение параметра. Помогает оценить неопределенность в оценках метрик модели.
Бутстрап
Метод повторной выборки с возвращением для оценки распределения статистики. Позволяет оценить доверительные интервалы и стандартные ошибки без предположений о распределении данных. Мощный непараметрический метод.
Главные компоненты (PCA)
Метод снижения размерности, который находит направления наибольшей вариации в данных. Использует собственные векторы ковариационной матрицы. Помогает визуализировать высокоразмерные данные и уменьшить количество признаков.
Распространенные ошибки
Понимание статистики помогает избежать распространенных ошибок в машинном обучении. Одна из самых частых - это переобучение, когда модель слишком хорошо подстраивается под обучающие данные и плохо работает на новых данных. Статистические методы, такие как кросс-валидация и регуляризация, помогают обнаружить и предотвратить переобучение.
Другая распространенная ошибка - это утечка данных (data leakage), когда информация из тестовой выборки случайно попадает в обучающую. Это приводит к завышенным оценкам качества модели. Правильное разделение данных и понимание временной структуры данных помогают избежать этой проблемы.
Проблема множественного тестирования возникает, когда мы проводим много статистических тестов одновременно. Даже если нулевая гипотеза верна, при уровне значимости 5% мы ожидаем, что 5% тестов дадут ложноположительный результат. Методы коррекции, такие как поправка Бонферрони, помогают контролировать общую вероятность ошибки первого рода.
Визуализация данных
Визуализация - это мощный инструмент статистического анализа. Хорошая визуализация может выявить закономерности, которые трудно обнаружить с помощью численных методов. Гистограммы показывают распределение данных, диаграммы рассеяния - взаимосвязи между переменными, временные ряды - тренды и сезонность.
Важно выбирать правильный тип визуализации для данных. Для категориальных данных подходят столбчатые диаграммы и круговые диаграммы. Для непрерывных данных - гистограммы и ящики с усами. Для связей между переменными - диаграммы рассеяния и тепловые карты корреляций.
Визуализация также важна для интерпретации моделей. Графики важности признаков показывают, какие признаки наиболее влияют на предсказания модели. Графики остатков в регрессии помогают проверить предположения модели. Кривые ROC визуализируют компромисс между истинно положительными и ложноположительными срабатываниями в классификации.
Важное уведомление: Этот сайт носит исключительно информационный характер и не предоставляет образовательных услуг.
Пожалуйста, ознакомьтесь с нашими Отказом от ответственности и Политикой конфиденциальности.